


728x90
1. Metrics-server
- kubelet 설치 시 포함되는 cAdvisor를 통하여 컨테이너 metric수집

[metric-server 설치 및 확인]
# 배포 : addon 으로 배포되어 있음
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l app.kubernetes.io/name=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'2. kwatch
- 다양한 외부 채널의 webhook 설정을 통해 발생하는 알람을 확인
[설치 및 확인]
# 닉네임
NICK=<각자 자신의 닉네임>
NICK=yjsong
# configmap 생성
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/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'
title: $NICK-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
[webhook 확인]
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-19
spec:
containers:
- name: nginx-pod
image: nginx:1.19.19 # 존재하지 않는 이미지 버전
EOF
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
# 삭제
kubectl delete pod nginx-19
# (옵션) 노드1번 강제 재부팅 해보기
ssh $N1 sudo reboot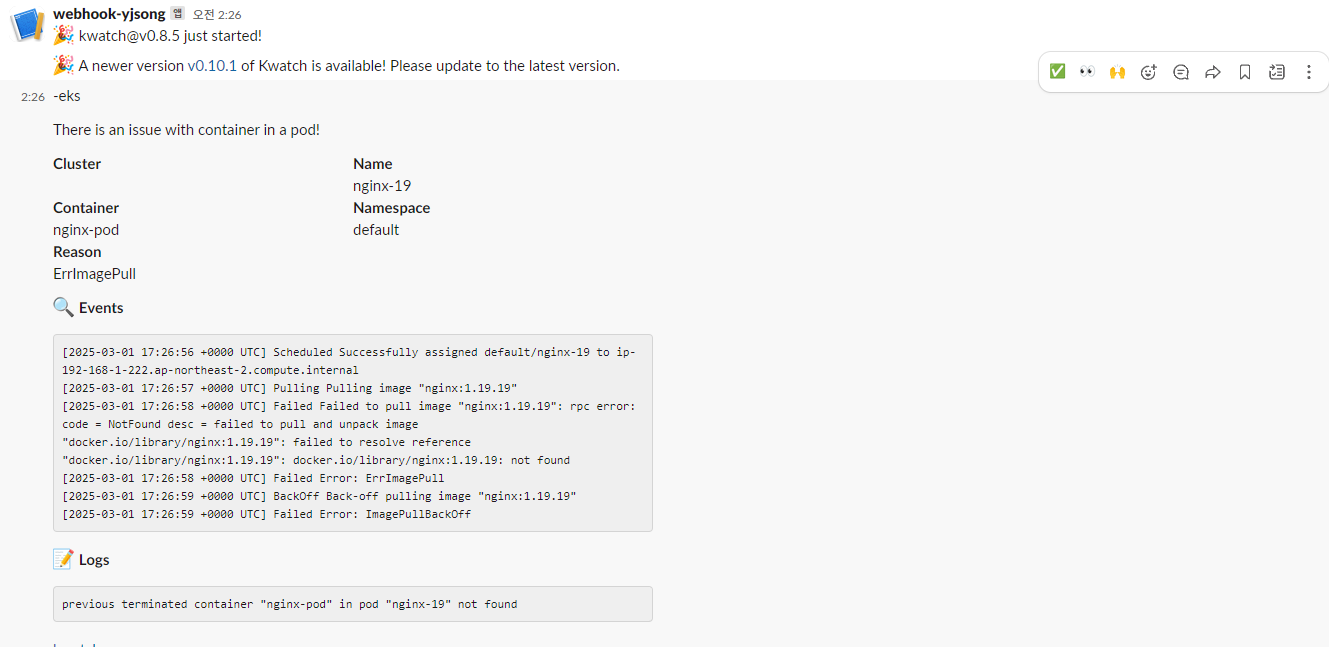

3. Prometheus(★★★)
- 오픈소스 Monitoring & Alert Tool


- Prometheus Server에서 Target의 metric을 Pull방식으로 가져와서 TSDB(시계열 데이터베이스) 저장
- PromQL: 프로메테우스 자체 쿼리 렝귀지 제공
- Service discovery를 통해 Target을 자동 등록
- Grafana는 Prometheus에서 수집한 metric를 가져와서 시각화
- Prometheus 자체 Alertmanager를 통하여 알람을 받을 수 있음
[ 설치(운영서버/직접설치) ]
- 수동을 target을 등록하기에는 한계가 있음
# 최신 버전 다운로드
wget https://github.com/prometheus/prometheus/releases/download/v3.2.0/prometheus-3.2.0.linux-amd64.tar.gz
# 압축 해제
tar -xvf prometheus-3.2.0.linux-amd64.tar.gz
cd prometheus-3.2.0.linux-amd64
ls -l
#
mv prometheus /usr/local/bin/
mv promtool /usr/local/bin/
mkdir -p /etc/prometheus /var/lib/prometheus
mv prometheus.yml /etc/prometheus/
cat /etc/prometheus/prometheus.yml
#
useradd --no-create-home --shell /sbin/nologin prometheus
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
chown prometheus:prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
#
tee /etc/systemd/system/prometheus.service > /dev/null <<EOF
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--web.listen-address=0.0.0.0:9090
[Install]
WantedBy=multi-user.target
EOF
#
systemctl daemon-reload
systemctl enable --now prometheus
systemctl status prometheus
ss -tnlp
#
curl localhost:9090/metrics
echo -e "http://$(curl -s ipinfo.io/ip):9090"

[node_exporter 설치]
- 별도 Node의 상태 정보를 수집(OS metric)
# Node Exporter 최신 버전 다운로드
cd ~
wget https://github.com/prometheus/node_exporter/releases/download/v1.9.0/node_exporter-1.9.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.9.0.linux-amd64.tar.gz
cd node_exporter-1.9.0.linux-amd64
cp node_exporter /usr/local/bin/
#
groupadd -f node_exporter
useradd -g node_exporter --no-create-home --shell /sbin/nologin node_exporter
chown node_exporter:node_exporter /usr/local/bin/node_exporter
#
tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
Documentation=https://prometheus.io/docs/guides/node-exporter/
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
Restart=on-failure
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=:9200
[Install]
WantedBy=multi-user.target
EOF
# 데몬 실행
systemctl daemon-reload
systemctl enable --now node_exporter
systemctl status node_exporter
ss -tnlp
#
curl localhost:9200/metrics
[prometheus 설정에 수집 대상 target (node_exporter) 추가]
# prometheus.yml 수정
cat << EOF >> /etc/prometheus/prometheus.yml
- job_name: 'node_exporter'
static_configs:
- targets: ["127.0.0.1:9200"]
labels:
alias: 'myec2'
EOF
# prometheus 데몬 재기동
systemctl restart prometheus.service
systemctl status prometheus
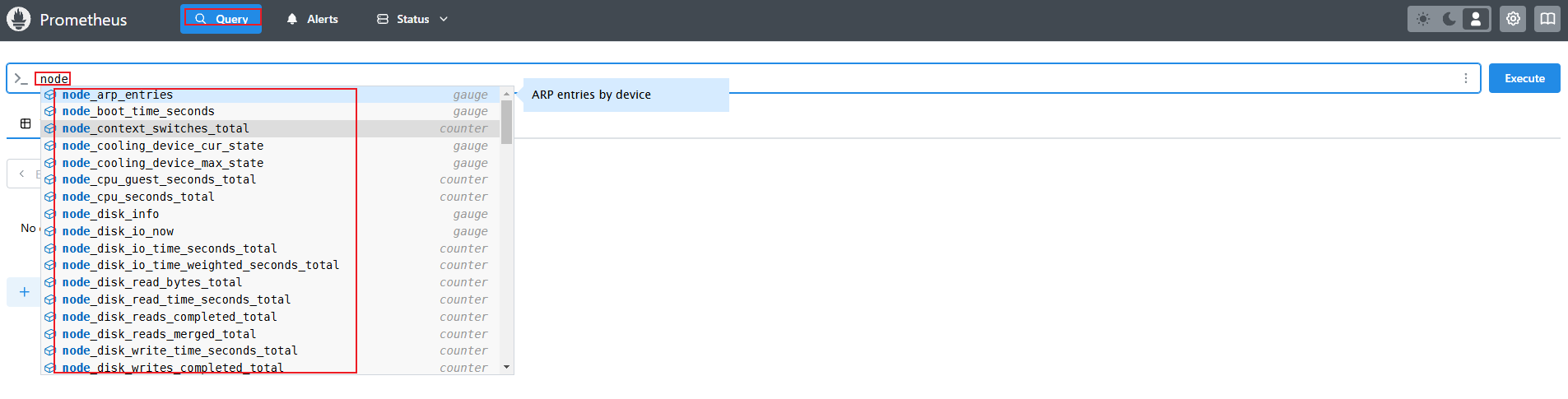
[ prometheus 웹에서 target 확인 및 node 로 시작되는 메트릭 쿼리 해보기 ]
rate(node_cpu_seconds_total{mode="system"}[1m])
node_filesystem_avail_bytes
rate(node_network_receive_bytes_total[1m])
[ 프로메테우스-스택 설치]
- 모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값/수준)
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
alertmanager:
enabled: false
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana-0 : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get sts,ds,deploy,pod,svc,ep,ingress,pvc,pv -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
kubectl df-pv
# 프로메테우스 버전 확인
echo -e "https://prometheus.$MyDomain/api/v1/status/buildinfo"
open https://prometheus.$MyDomain/api/v1/status/buildinfo # macOS
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version
prometheus, version 3.1.0 (branch: HEAD, revision: 7086161a93b262aa0949dbf2aba15a5a7b13e0a3)
...
# 프로메테우스 웹 접속
echo -e "https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" # macOS
# 그라파나 웹 접속
echo -e "https://grafana.$MyDomain"
open "https://grafana.$MyDomain" # macOS

[AWS CNI Metrics 수집을 위한 사전 설정]
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat
# metrics url 접속 확인
curl -s $N1:61678/metrics | grep '^awscni'

- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 프로메테우스는 해당 경로에 HTTP GET 방식으로 metric 정보를 가져와 TSDB에저장
# 아래 처럼 프로메테우스가 각 서비스의 포트 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# (노드 익스포터 경우) 노드의 9100번 포트의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" macOS
# 웹 상단 주요 메뉴 설명
1. 쿼리(Query) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
2. 경고(Alerts) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전 정보
[Status > configuration]

- JOB단위로 어떤 metric을 가져올 건지 설정(job name 을 기준으로 scraping)
- SD(ServiceDiscovery)설정을 통해 네임스페이스와 포트번호를 구분하여 metric을 가져옴
※ 수동으로 타겟을 설정하지 않아도 SD때문에 자동으로 타겟이 등록
[서비스모니터 동작]

[전체 메트릭 대상(Targets) 확인 : Status → Target health]
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
- 현재 각 Target 클릭 시 메트릭 정보 확인
# serviceMonitor/monitoring/kube-prometheus-stack-kube-proxy/0 (3/3 up) 중 노드1에 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
ssh $N1 curl -s http://localhost:10249/metrics
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="4.194304e+06"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="1.6777216e+07"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="+Inf"} 1
rest_client_response_size_bytes_sum{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 626
rest_client_response_size_bytes_count{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 1
...
# [운영서버 EC2] serviceMonitor/monitoring/kube-prometheus-stack-api-server/0 (2/2 up) 중 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
>> 해당 IP주소는 어디인가요?, 왜 apiserver endpoint는 2개뿐인가요? , 아래 메트릭 수집이 되게 하기 위해서는 어떻게 하면 될까요?
# [운영서버 EC2] 그외 다른 타켓의 Endpoint 로 접속 확인 가능 : 예시) 아래는 coredns 의 Endpoint 주소 (접속 주소는 실습 환경에 따라 다름)
[root@operator-host ~]# curl -s http://192.168.2.71:9153/metrics | tail -n 5
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 1.325232128e+09
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19

[메트릭을 그래프(Graph)로 조회]
- Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인

728x90
'2025_AEWS Study' 카테고리의 다른 글
| 4주차 - EKS Observability(4) Grafana (0) | 2025.03.02 |
|---|---|
| 4주차 - EKS Observability(3) Prometheus (0) | 2025.03.02 |
| 4주차 - EKS Observability(1) Logging (0) | 2025.03.01 |
| 3주차 - EKS Storage & Managed Node Groups(4)(NodeGroup) (0) | 2025.02.23 |
| 3주차 - EKS Storage & Managed Node Groups(3)(AWS EBS, EFS Controller) (0) | 2025.02.19 |