


Control Plane(Master Node) pod 로깅
- EKS의 Control Plane의 경우 AWS가 관리(사용자 관리 X)
- EKS Console 내 관찰성 부분에 Control Plane의 각 항목을 활성화 하여 Cloud Watch를 통해 로깅 가능

[ AWS CLI 명령어를 통하여 제어 플레인 로깅 활성화 ]
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'

[ CloudWatch에서 제어 플레인 로그 확인 ]

[ CloudWatch Logs Insights에서 다양한 쿼리 실행 ]
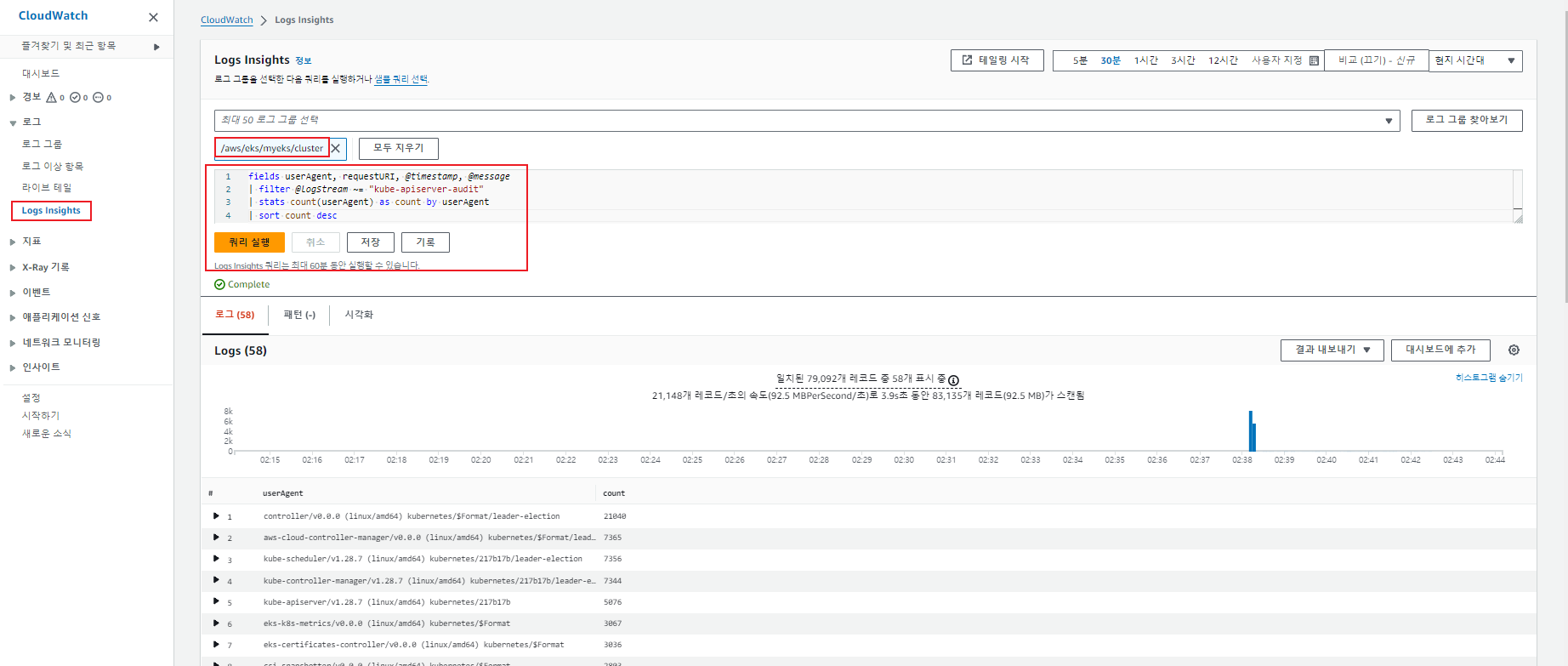
[ CloudWatch Logs Insights쿼리 예제 ]
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc
Data Plane(Worker Node) Pod 로깅
[ Logging 실습을 위한 Nginx Pod 배포 ]
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성 : 인증서 ARN 지정하지 않아도 가능! 혹시 https 리스너 설정 안 될 경우 인증서 설정 추가(주석 제거)해서 배포 할 것
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
#alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 15.14.0 -f nginx-values.yaml
[ kubectl 명령어를 통한 log 확인 ]
(yjsong@myeks:default) [root@myeks-bastion ~]# kubectl logs deploy/nginx -f
Defaulted container "nginx" out of: nginx, preserve-logs-symlinks (init)
nginx 16:44:20.62 INFO ==>
nginx 16:44:20.62 INFO ==> Welcome to the Bitnami nginx container
nginx 16:44:20.63 INFO ==> Subscribe to project updates by watching https://github.com/bitnami/containers
nginx 16:44:20.63 INFO ==> Submit issues and feature requests at https://github.com/bitnami/containers/issues
nginx 16:44:20.63 INFO ==>
nginx 16:44:20.63 INFO ==> ** Starting NGINX setup **
nginx 16:44:20.64 INFO ==> Validating settings in NGINX_* env vars
Certificate request self-signature ok
subject=CN = example.com
nginx 16:44:22.74 INFO ==> No custom scripts in /docker-entrypoint-initdb.d
nginx 16:44:22.74 INFO ==> Initializing NGINX
realpath: /bitnami/nginx/conf/vhosts: No such file or directory
nginx 16:44:22.76 INFO ==> ** NGINX setup finished! **
nginx 16:44:22.77 INFO ==> ** Starting NGINX **
192.168.3.30 - - [30/Mar/2024:16:46:12 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.3.30 - - [30/Mar/2024:16:46:27 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.3.30 - - [30/Mar/2024:16:46:42 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.1.183 - - [30/Mar/2024:16:46:46 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.3.30 - - [30/Mar/2024:16:46:57 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.1.183 - - [30/Mar/2024:16:47:01 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.3.30 - - [30/Mar/2024:16:47:12 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
192.168.3.30 - - [30/Mar/2024:16:47:13 +0000] "GET / HTTP/1.1" 200 409 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36" "211.227.99.112"
2024/03/30 16:47:13 [error] 52#52: *57 open() "/opt/bitnami/nginx/html/favicon.ico" failed (2: No such file or directory), client: 192.168.3.30, server: , request: "GET /favicon.ico HTTP/1.1", host: "nginx.burst89.com", referrer: "https://nginx.burst89.com/"
kubectl logs 또는 docker logs 명령어를 통하여 pod의 로그를 볼 수 있는 이유는 컨테이너 빌드 시 stdout / stderr으로 로그가 심볼릭 링크 설정이 되어 있기 때문에 logs 명령어를 통해 pod/container에 접속하지 않아도 확인 할 수 있음.
[ Nginx Pod 의 로그 설정 부분]
(yjsong@myeks:default) [root@myeks-bastion ~]# kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
Defaulted container "nginx" out of: nginx, preserve-logs-symlinks (init)
total 0
lrwxrwxrwx 1 1001 1001 11 Mar 30 16:44 access.log -> /dev/stdout
lrwxrwxrwx 1 1001 1001 11 Mar 30 16:44 error.log -> /dev/stderr
RUN ln -sf /dev/stdout /opt/bitnami/nginx/logs/access.log
RUN ln -sf /dev/stderr /opt/bitnami/nginx/logs/error.log
이러한 logs 명령어를 통하여 pod의 로그를 빠르고 쉽게 확인 할 수 있지만 Pod 종료 또는 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하면 확인 할 수 없다는 단점이 있다.
[ 솔루션을 통한 Pod 로깅 ]
1. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
- AWS에서 제공하는 Logging 솔루션
- 각 노드에 CloudWatch agent pod가 Application 컨테이너의 metric을 수집 & Fluent bit pod가 Application 컨테이너의 log를 수집

[ 설치 및 확인 ]
# EKS Addon 설치
aws eks create-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observability
aws eks list-addons --cluster-name myeks --output table
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatch
kubectl describe clusterrole cloudwatch-agent-role amazon-cloudwatch-observability-manager-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding amazon-cloudwatch-observability-manager-rolebinding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l app.kubernetes.io/component=amazon-cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
# cloudwatch-agent 설정 확인
kubectl describe cm cloudwatch-agent-agent -n amazon-cloudwatch
(yjsong@myeks:default) [root@myeks-bastion ~]# kubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatch
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/cloudwatch-agent 3 3 3 3 3 <none> 23m
daemonset.apps/dcgm-exporter 0 0 0 0 0 <none> 23m
daemonset.apps/fluent-bit 3 3 3 3 3 <none> 23m
NAME READY STATUS RESTARTS AGE
pod/amazon-cloudwatch-observability-controller-manager-8544df7r745q 1/1 Running 0 23m
pod/cloudwatch-agent-r9qg8 1/1 Running 0 23m
pod/cloudwatch-agent-s7b2j 1/1 Running 0 23m
pod/cloudwatch-agent-wdw6r 1/1 Running 0 23m
pod/fluent-bit-hgsxj 1/1 Running 0 23m
pod/fluent-bit-p7zmx 1/1 Running 0 23m
pod/fluent-bit-sbwfd 1/1 Running 0 23m
[ 수집 내용 ]
Fluentbit 컨테이너 데몬셋을 통하여 수집 대상의 로그를 CloudWatch Logs에 전송
- Application 로그 소스 → /var/log/containers
- host 로그 소스 → /var/log/dmesg, /var/log/secure, /var/log/messages
- dataplane 로그 소스 → /var/log/journal for kubelet.service,kubeproxy.service, docker.service
- performance
[ 저장 ]
CloudWatch Logs에 로그를 저장

[ CloudWatch 노드그룹을 통한 pod 로그 확인 ]
#Apachebench를 통한 부하 발생
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/
[ 시각화 ]
CloudWatch의 Logs Insights를 통하여 대상 로그 분석 및 시각화

CloudWatch의 인사이트 Container Insights를 EKS의 다양한 로그를 확인 할 수 있음

2. Metrics-server & kwatch & botkube
- kubelet 설치 시 포함되는 cAdvisor를 통하여 컨테이너 metric수집

[ 설치 및 확인 ]
# 배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
kubectl top pod -n kube-system --sort-by='cpu'
kubectl top pod -n kube-system --sort-by='memory'
(yjsong@myeks:default) [root@myeks-bastion ~]# kubectl get pod -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-6d94bc8694-gzwwm 1/1 Running 0 99s
(yjsong@myeks:default) [root@myeks-bastion ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-1-52.ap-northeast-2.compute.internal 64m 1% 677Mi 4%
ip-192-168-2-207.ap-northeast-2.compute.internal 67m 1% 804Mi 5%
ip-192-168-3-51.ap-northeast-2.compute.internal 62m 1% 794Mi 5%3. kwatch
- webhook 설정을 통해 발생하는 알람을 확인
[ 설치 ]
# 닉네임
NICK=yjsong
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'SLACK WEBHOOK URL'
title: $NICK-EKS
#text: Customized text in slack message
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
[ webhook 확인 ]
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
4. Prometheus(★★★)


Prometheus Server에서 Target의 metric을 가져와서 TSDB 저장
- Grafana는 Prometheus에서 수집한 metric를 가져와서 시각화
- Prometheus 자체 Alertmanager를 통하여 알람을 받을 수 있음
[ 설치 ]
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인 : 정상 상태 확인(만료 상태면 에러 발생!)
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 57.1.0 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring


Nginx, Prometheus, Grafna 총3개의 ALB를 생성하였지만 aws console에서는 1개의 ALB에 규칙을 통하여 각 서비스 대상그룹으로 분기
[ PodMonitor 설치 - aws-cni metric 수집 ]
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat | yh
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
# metrics url 접속 확인
curl -s $N1:61678/metrics | grep '^awscni'
→ Node export: Node의 정보를 Prometheus가 수집할 수 있게 도와주는 Agent
→ 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
→ 프로메테우스는 해당 경로에 HTTP GET 방식으로 metric 정보를 가져와 TSDB에저장
Status > configuration

→ JOB단위로 어떤 metric을 가져올 건지 설정
→ SD(ServiceDiscovery)설정을 통해 네임스페이스와 포트번호를 구분하여 metric을 가져옴
※ 수동으로 타겟을 설정하지 않아도 SD때문에 자동으로 타겟이 등록
[ PromQL 사용법 ]
→ Node-exporter metric
ex) node 입력 시 팝업되는 값들은 모두 node-exporter에 의해 수집되는 metric

node_memory_Active_bytes
node_memory_Active_bytes{instance="192.168.3.51:9100"}
자동완성 기능을 통해 편하게 metric을 선택 할 수 있음.


→ kube-state-metric
쿠버네티스 API 통신을 하여 cronjob, deployments, stateful set 정보를 가져옴
ex) kube 입력 시 팝업되는 값들은 모두 kube-state-metric에 의해 수집되는 metric
kube_deployment_status_replicas_available
kube_deployment_status_replicas_available{deployment="coredns"}
→ kube-proxy
ex) kubeproxy 입력 시 팝업되는 값들은 모두 kube-proxy에 의해 수집되는 metric
kubeproxy_sync_proxy_rules_iptables_total{table="nat"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="192.168.3.51:10249"}
[ Application Metric 쿼리 - Nginx ServiceMonitor ]

→ ServiceMonitor가 PodMonitor보다 상위 개념으로 더 많이 사용되고 동적으로 파드가 증가 및 삭제 되는 경우에도 자동으로 로깅 가능
[ Nginx의 ServiceMonitor 설정 ]
# 모니터링
watch -d "kubectl get pod; echo; kubectl get servicemonitors -n monitoring"
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
→ Nginx Pod의 Sidecar(웹 서버 역할) 설정을 하여 해당 pod에서 metric 데이터를 Prometheus 서버에 제공!
→ 설정 완료 시 Prometheus스택에서 자동 반영
- Target 확인 시 ServiceMonitor/nginx 부분이 추가된 것을 확인

- Configuration 확인 시 job_name에 serviceMonitor/nginx 추가된것을 확인

→ 자동으로 Target 등록 및 Configuration에 Job이 설정되는 이유는 Prometheus 서버 pod 확인 시 config-reloader 컨테이가 존재. 설정이 변경되면 자동으로 적용

5. Grafana(★★★)
- TBSD데이터를 시각화 / 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
- Prometheus에서 수집한 Metric을 시각화 / Prometheus 스텍 설치 시 스텍에 포함되어 설치
[ 기본 대시보드 ]
- 스택을 통해서 설치된 기본 대시보드

[ 공식 대시보드 가져오기 ]
이미 만들어 진 대시보드를 Import 하여 사용 / Dashboard → New → Import → "대시보드 번호" 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import
→ 15757 추천 - Kubernetes / Views / Global

→ 17900 추천 - 1 Kubernetes All-in-one Cluster Monitoring KR(v1.26.0)

→ No data 부분 수정
On-Promise 환경과 AWS 환경 차이로 쿼리 내용 중 "node"를 "instance"로 변경


→ 16032 추천 - AWS CNI Metrics

→ 12708 추천 - NGINX exporter

[ Panel 생성 - 커스텀 대시보드 ]
- 대시보드 내 다양한 Panel 구성할 수 있음
- 쿼리를 PromQL 또는 Builder를 통해 실행
→ Time series panel 예제
node_cpu_seconds_total
rate(node_cpu_seconds_total[5m])
sum(rate(node_cpu_seconds_total[5m]))
sum(rate(node_cpu_seconds_total[5m])) by (instance)
→ Bar chart panel 예제
kube_deployment_status_replicas_available
count(kube_deployment_status_replicas_available) by (namespace)
→ Stat panel 예제
kube_deployment_spec_replicas
kube_deployment_spec_replicas{deployment="nginx"}
# scale out
kubectl scale deployment nginx --replicas 6
→ Gauge panel 예제
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}[1m]
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
rate(node_cpu_seconds_total{mode="idle"}[1m])
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))
→ Table panel 예제
node_os_info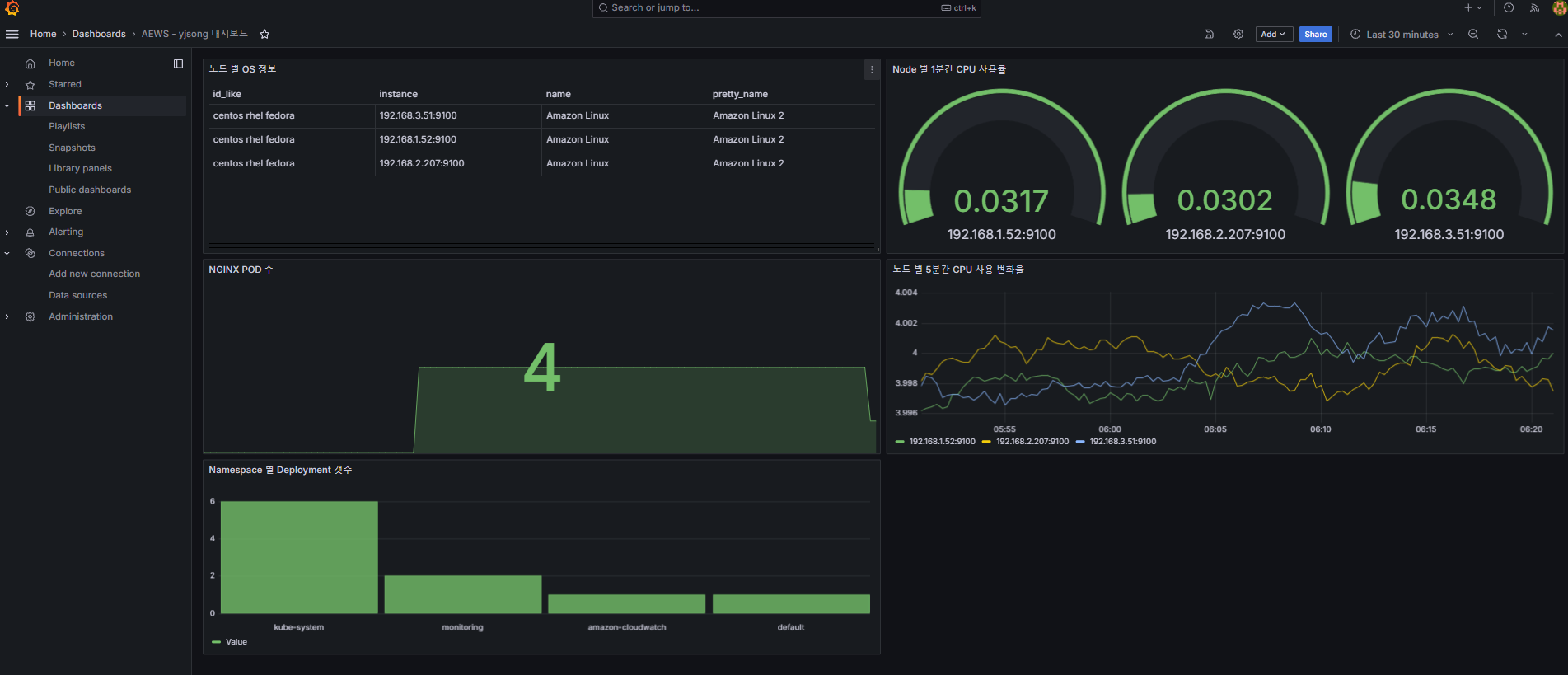
[ Alert ]

[ nginx alert 실습 ]
- 그라파나 → Alerting → Alert ruels → Create alert rule : nginx 웹 요청 1분 동안 누적 60 이상 시 Alert 설정
1. Rule 설정

2. Contact points 설정

3. nginx 반복 접속 실행 후 슬랙 채널 알람 확인
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done

'AEWS Study' 카테고리의 다른 글
| 5주차 - EKS Autoscaling - (Node Autoscaling) (0) | 2024.04.05 |
|---|---|
| 5주차 - EKS Autoscaling - (Pod Autoscaling) (0) | 2024.04.05 |
| 3주차 - EKS Storage & Nodegroup (0) | 2024.03.24 |
| 2주차 - EKS Networking (0) | 2024.03.16 |
| 1주차 - Amzaon EKS 설치 및 기본 사용 (0) | 2024.03.10 |