

728x90
Karpenter
고성능의 지능형 k8s 컴퓨팅 프로비저닝 및 관리 솔루션, 수초 이내에 대응 가능, 더 낮은 컴퓨팅 비용으로 노드 선택
- 지능형의 동적인 인스턴스 유형 선택 - Spot, AWS Graviton 등
- 자동 워크로드 Consolidation 기능
- 일관성 있는 더 빠른 노드 구동시간을 통해 시간/비용 낭비 최소화
- 동작

- Consolidation
- Consolidation 동작 방식
- 중단 비용 - 예) 파드가 많이 배치되어서 재스케줄링 영향이 큰 경우 등 , 오래 기동된 노드 TTL, 비용 관련
- 관리 간소화
CA의 경우 AWS ASG와 CA 모두 동작을 해야 하기 때문에 시간이 오래 걸림
ASG의 경우 주체가 AWS이고, CA의 경우 EKS가 주체이기 때문에 각 각 확인을 해야 함
Karpenter의 경우 ASG를 사용하지 않고 Karpenter 자체적으로 동작하기 때문에 CA보다 훨씬 빠르게 동작
Karpenter 설치
- 기존 배포한 EKS 삭제 후 새로운 EKS 배포
# 변수 설정
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.2.1"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="yjsong-karpenter-demo" # ${USER}-karpenter-demo
export AWS_DEFAULT_REGION="ap-northeast-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
# 확인
echo "${KARPENTER_NAMESPACE}" "${KARPENTER_VERSION}" "${K8S_VERSION}" "${CLUSTER_NAME}" "${AWS_DEFAULT_REGION}" "${AWS_ACCOUNT_ID}" "${TEMPOUT}" "${ALIAS_VERSION}"
# CloudFormation 스택으로 IAM Policy/Role, SQS, Event/Rule 생성 : 3분 정도 소요
## IAM Policy : KarpenterControllerPolicy-gasida-karpenter-demo
## IAM Role : KarpenterNodeRole-gasida-karpenter-demo
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > "${TEMPOUT}" \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
# 클러스터 생성 : EKS 클러스터 생성 15분 정도 소요
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "${K8S_VERSION}"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}
iamIdentityMappings:
- arn: "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
## If you intend to run Windows workloads, the kube-proxy group should be specified.
# For more information, see https://github.com/aws/karpenter/issues/5099.
# - eks:kube-proxy-windows
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2023
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
iam:
withAddonPolicies:
externalDNS: true
addons:
- name: eks-pod-identity-agent
EOF
# eks 배포 확인
eksctl get cluster
eksctl get nodegroup --cluster $CLUSTER_NAME
eksctl get iamidentitymapping --cluster $CLUSTER_NAME
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
eksctl get addon --cluster $CLUSTER_NAME
#
kubectl ctx
kubectl config rename-context "<각자 자신의 IAM User>@<자신의 Nickname>-karpenter-demo.ap-northeast-2.eksctl.io" "karpenter-demo"
kubectl config rename-context "admin@gasida-karpenter-demo.ap-northeast-2.eksctl.io" "karpenter-demo"
# k8s 확인
kubectl ns default
kubectl cluster-info
kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
kubectl get pod -n kube-system -owide
kubectl get pdb -A
kubectl describe cm -n kube-system aws-auth
# EC2 Spot Fleet의 service-linked-role 생성 확인 : 만들어있는것을 확인하는 거라 아래 에러 출력이 정상!
# If the role has already been successfully created, you will see:
# An error occurred (InvalidInput) when calling the CreateServiceLinkedRole operation: Service role name AWSServiceRoleForEC2Spot has been taken in this account, please try a different suffix.
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
실습 동작 확인을 위한 도구 설치 : kube-ops-view
- 실습 동작 확인을 위한 도구 설치 : kube-ops-view
- 실습 동작 확인을 위한 도구 설치 : kube-ops-view
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=LoadBalancer --set env.TZ="Asia/Seoul" --namespace kube-system
echo -e "http://$(kubectl get svc -n kube-system kube-ops-view -o jsonpath="{.status.loadBalancer.ingress[0].hostname}"):8080/#scale=1.5"
Install Karpenter
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
# Karpenter 설치를 위한 변수 설정 및 확인
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
echo "${CLUSTER_ENDPOINT} ${KARPENTER_IAM_ROLE_ARN}"
# karpenter 설치
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
# 확인
helm list -n kube-system
kubectl get-all -n $KARPENTER_NAMESPACE
kubectl get all -n $KARPENTER_NAMESPACE
kubectl get crd | grep karpenter
ec2nodeclasses.karpenter.k8s.aws 2025-03-02T06:11:47Z
nodeclaims.karpenter.sh 2025-03-02T06:11:47Z
nodepools.karpenter.sh 2025-03-02T06:11:47Z
- Karpenter는 ClusterFirst기본적으로 포드 DNS 정책을 사용합니다. Karpenter가 DNS 서비스 포드의 용량을 관리해야 하는 경우 Karpenter가 시작될 때 DNS가 실행되지 않음을 의미
- Pod DNS 정책을 Defaultwith 로 설정 --set dnsPolicy=Default
- Karpenter가 내부 DNS 확인 대신 호스트의 DNS 확인을 사용하도록 하여 실행할 DNS 서비스 포드에 대한 종속성이 없도록 함
- Karpenter는 노드 용량 추적을 위해 클러스터의 CloudProvider 머신과 CustomResources 간의 매핑을 만듭니다. 이 매핑이 일관되도록 하기 위해 Karpenter는 다음 태그 키를 활용합니다.
- karpenter.sh/managed-by
- karpenter.sh/nodepool
- kubernetes.io/cluster/${CLUSTER_NAME}
프로메테우스 / 그라파타 설치
#
helm repo add grafana-charts https://grafana.github.io/helm-charts
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create namespace monitoring
# 프로메테우스 설치
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/prometheus-values.yaml | envsubst | tee prometheus-values.yaml
helm install --namespace monitoring prometheus prometheus-community/prometheus --values prometheus-values.yaml
extraScrapeConfigs: |
- job_name: karpenter
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system
relabel_configs:
- source_labels:
- __meta_kubernetes_endpoints_name
- __meta_kubernetes_endpoint_port_name
action: keep
regex: karpenter;http-metrics
# 프로메테우스 얼럿매니저 미사용으로 삭제
kubectl delete sts -n monitoring prometheus-alertmanager
# 프로메테우스 접속 설정
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9090 &
open http://127.0.0.1:9090
# 그라파나 설치
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/grafana-values.yaml | tee grafana-values.yaml
helm install --namespace monitoring grafana grafana-charts/grafana --values grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
version: 1
url: http://prometheus-server:80
access: proxy
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
capacity-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-capacity-dashboard.json
performance-dashboard:
url: https://karpenter.sh/preview/getting-started/getting-started-with-karpenter/karpenter-performance-dashboard.json
# admin 암호
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
17JUGSjgxK20m4NEnAaG7GzyBjqAMHMFxRnXItLj
# 그라파나 접속
kubectl port-forward --namespace monitoring svc/grafana 3000:80 &
open http://127.0.0.1:3000
Create NodePool (구 Provisioner)
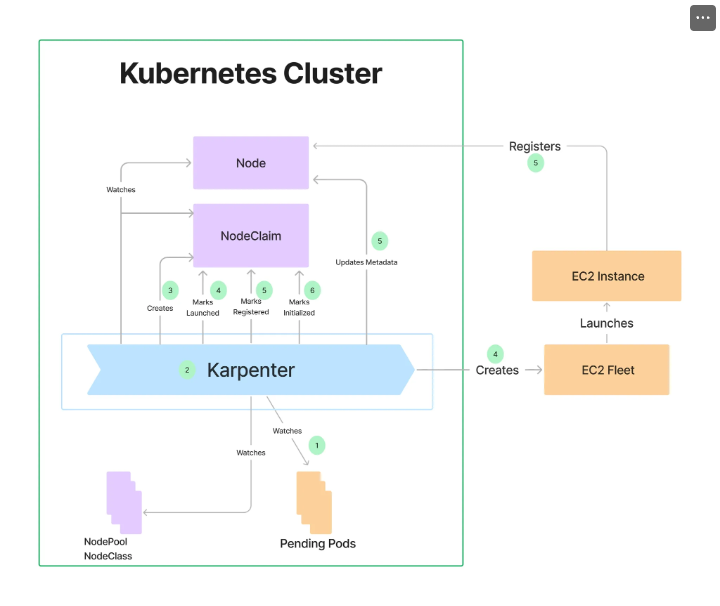
- 관리 리소스는 securityGroupSelector and subnetSelector로 찾음
- consolidationPolicy : 미사용 노드 정리 정책, 데몬셋 제외
- 단일 Karpenter NodePool은 여러 다른 포드 모양을 처리할 수 있습니다. Karpenter는 레이블 및 친화성과 같은 포드 속성을 기반으로 스케줄링 및 프로비저닝 결정
- Karpenter는 여러 다른 노드 그룹을 관리할 필요성을 제거
#
echo $ALIAS_VERSION
v20250228
#
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h # 30 * 24h = 720h
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@${ALIAS_VERSION}" # ex) al2023@latest
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass,nodeclaims
Karpenter 실습 (Scaling-Out)
- pause 파드 1개에 CPU 1개 최소 보장 할당할 수 있게 디플로이먼트 배포
- replicas 증가 시, Pending 상태 확인 후 빠르게 Node 추가 및 Pending Pod 배치
# pause 파드 1개에 CPU 1개 최소 보장 할당할 수 있게 디플로이먼트 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
# [신규 터미널] 모니터링
eks-node-viewer --resources cpu,memory
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true" --extra-labels eks-node-viewer/node-age
# Scale up
kubectl get pod
kubectl scale deployment inflate --replicas 5
# 출력 로그 분석해보자!
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
# 확인
kubectl get nodeclaims
kubectl describe nodeclaims
kubectl get node -l karpenter.sh/registered=true -o jsonpath="{.items[0].metadata.labels}" | jq '.'
# (옵션) 더욱 더 Scale up!
kubectl scale deployment inflate --replicas 30
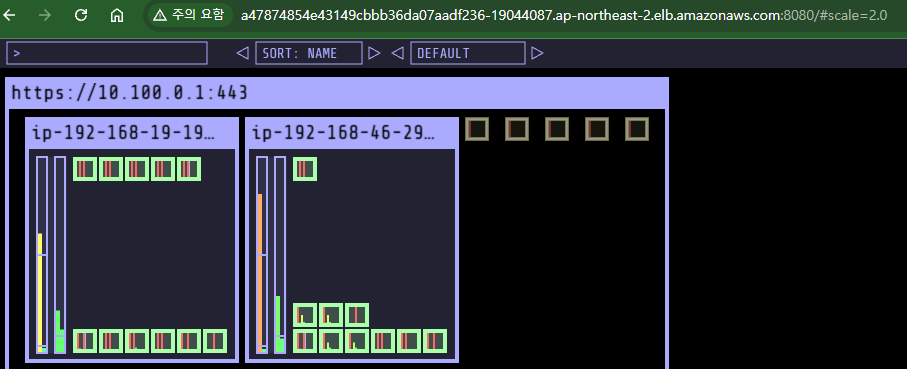
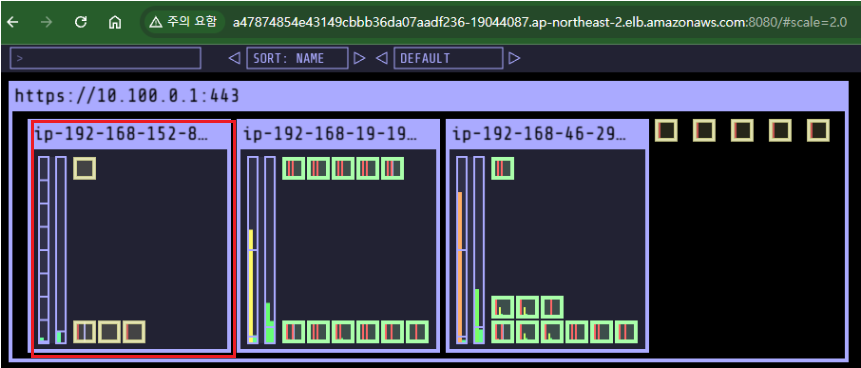

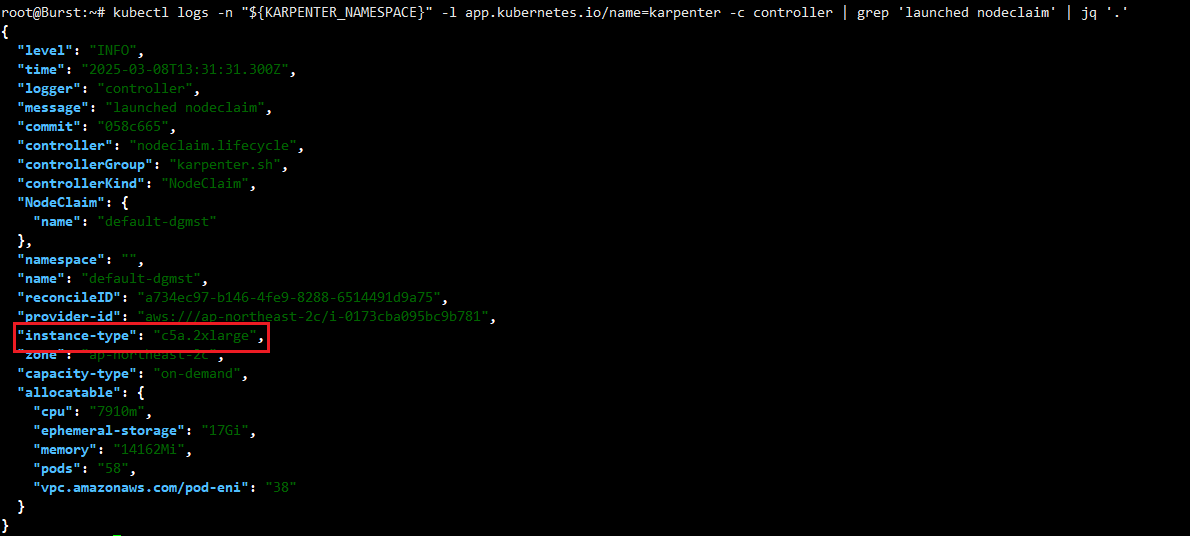
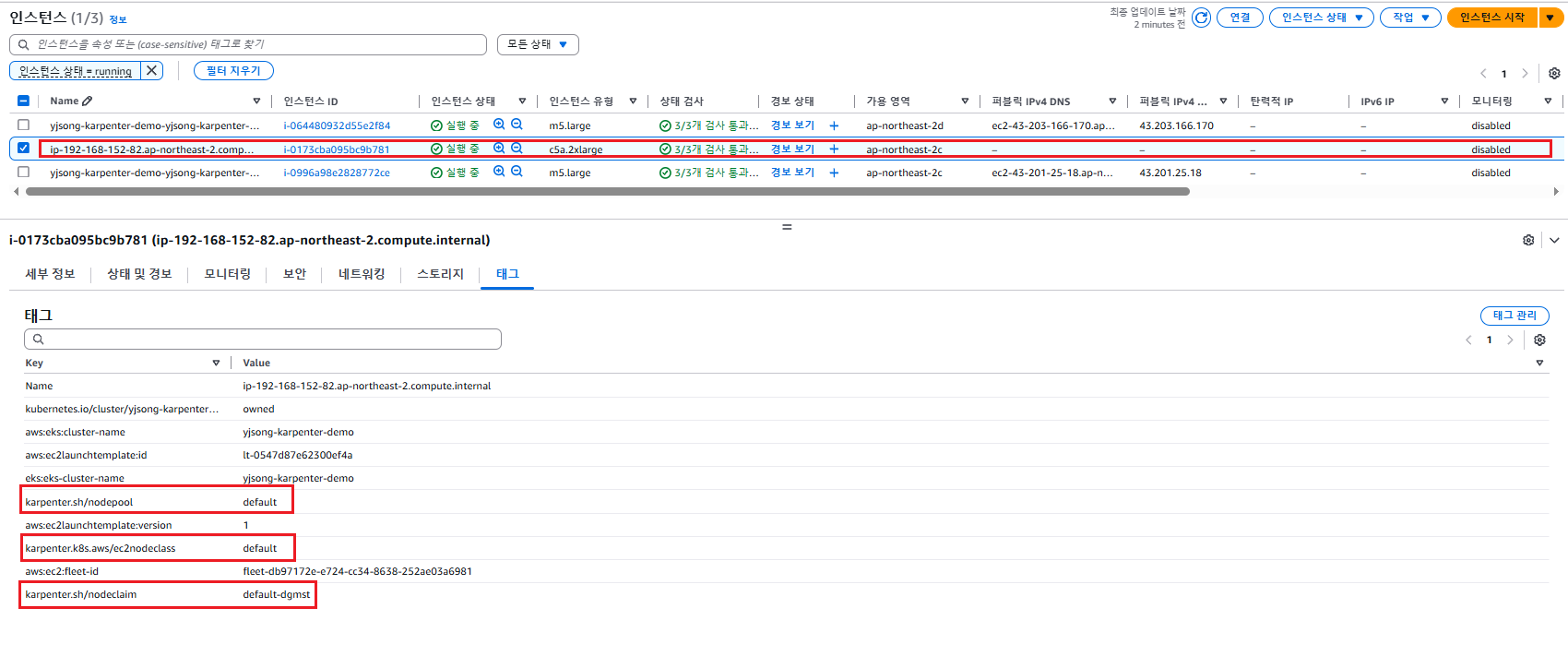
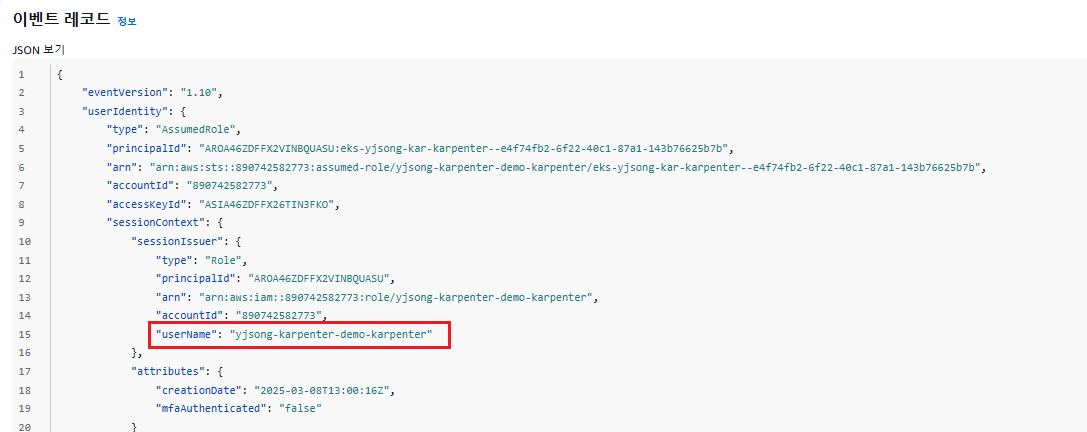
- 카펜터로 배포한 노드 tag 정보 참고
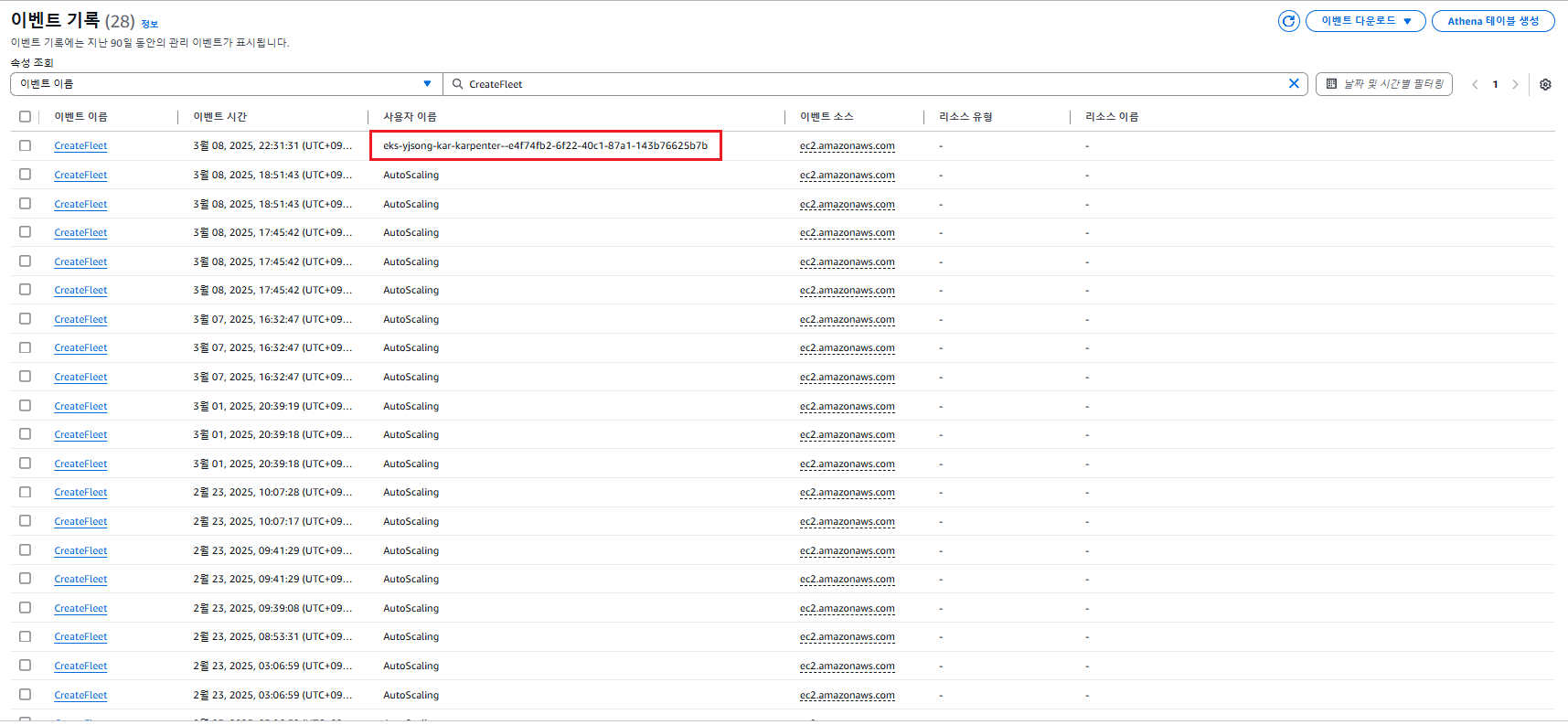
- CreateFleet 이벤트 확인
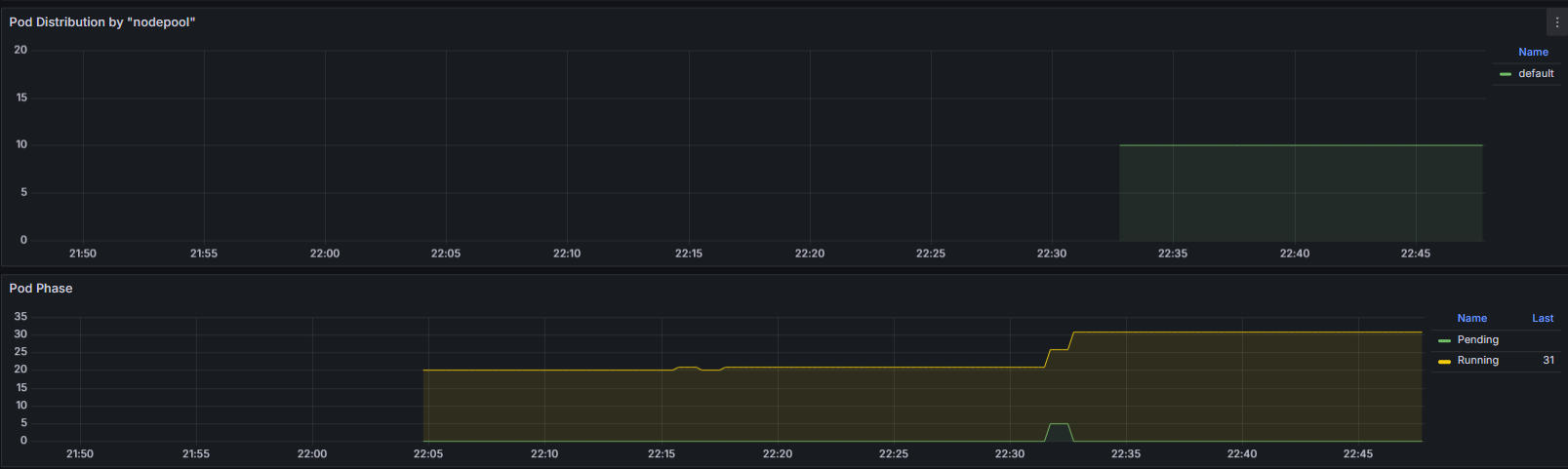
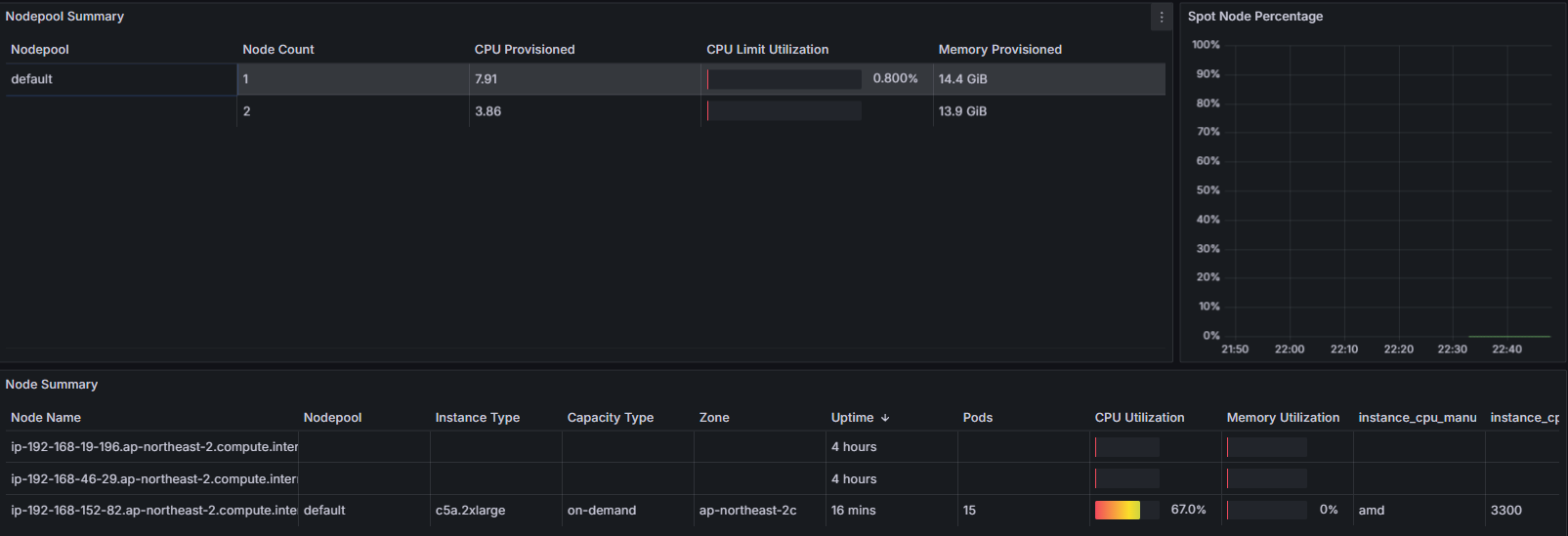
- Grafana 대시보드 확인
Karpenter 실습 (Scaling-In)
# Now, delete the deployment. After a short amount of time, Karpenter should terminate the empty nodes due to consolidation.
kubectl delete deployment inflate && date
# 출력 로그 분석해보자!
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
#
kubectl get nodeclaims
- Karpenter에 의해 추가된 Node 삭제 확인
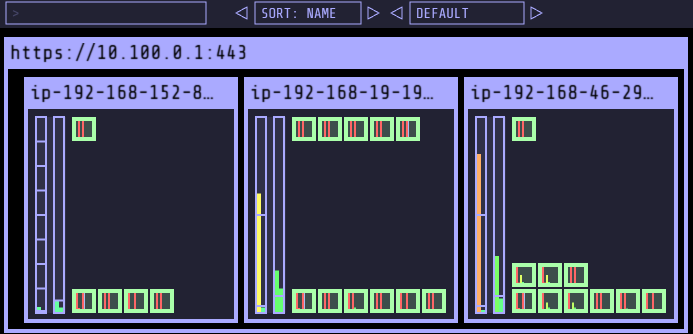

Disruption(구 Consolidation)
Node 최적화로 Karpenter가 자원이 남는 Node가 있으면 삭제하거나 또는 스펙을 줄임
- Expiration 만료 : 기본 720시간(30일) 후 인스턴스를 자동으로 만료하여 강제로 노드를 최신 상태로 유지
- Drift 드리프트 : 구성 변경 사항(NodePool, EC2NodeClass)를 감지하여 필요한 변경 사항을 적용
- Consolidation 통합 : 비용 효율적인 컴퓨팅 최적화 선택
- 스팟 인스턴스 시작 시 Karpenter는 AWS EC2 Fleet Instance API를 호출하여 NodePool 구성 기반으로 선택한 인스턴스 유형을 전달
- AWS EC2 Fleet Instance API는 시작된 인스턴스 목록과 시작할 수 없는 인스턴스 목록을 즉시 반환하는 API로, 시작할 수 없을 경우 Karpenter는 대체 용량을 요청하거나 워크로드에 대한 soft 일정 제약 조건을 제거할 수 있음
- Spot-to-Spot Consolidation 에는 주문형 통합과 다른 접근 방식이 필요
- 온디맨드 통합의 경우 규모 조정 및 최저 가격이 주요 지표로 사용
- 스팟 간 통합이 이루어지려면 Karpenter에는 최소 15개의 인스턴스 유형이 포함된 다양한 인스턴스 구성(연습에 정의된 NodePool 예제 참조)이 필요
- 이러한 제약 조건이 없으면 Karpenter가 가용성이 낮고 중단 빈도가 높은 인스턴스를 선택할 위험


- On-demand Consolidation 실습
# 기존 nodepool 삭제
kubectl delete nodepool,ec2nodeclass default
# 모니터링
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true" --extra-labels eks-node-viewer/node-age
watch -d "kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type"
# Create a Karpenter NodePool and EC2NodeClass
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
requirements:
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: karpenter.k8s.aws/instance-hypervisor
operator: In
values: ["nitro"]
expireAfter: 1h # nodes are terminated automatically after 1 hour
limits:
cpu: "1000"
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized # policy enables Karpenter to replace nodes when they are either empty or underutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "al2023@latest"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass
# Deploy a sample workload
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 5
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
memory: 1.5Gi
securityContext:
allowPrivilegeEscalation: false
EOF
- 확인 및 replicas 증가/감소
#
kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type
kubectl get nodeclaims
kubectl describe nodeclaims
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
# Scale the inflate workload from 5 to 12 replicas, triggering Karpenter to provision additional capacity
kubectl scale deployment/inflate --replicas 12
# This changes the total memory request for this deployment to around 12Gi,
# which when adjusted to account for the roughly 600Mi reserved for the kubelet on each node means that this will fit on 2 instances of type m5.large:
kubectl get nodeclaims
# Scale down the workload back down to 5 replicas
kubectl scale deployment/inflate --replicas 5
kubectl get nodeclaims
# We can check the Karpenter logs to get an idea of what actions it took in response to our scaling in the deployment. Wait about 5-10 seconds before running the following command:
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
# Karpenter can also further consolidate if a node can be replaced with a cheaper variant in response to workload changes.
# This can be demonstrated by scaling the inflate deployment replicas down to 1, with a total memory request of around 1Gi:
kubectl scale deployment/inflate --replicas 1
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl get nodeclaims
# 삭제
kubectl delete deployment inflate
kubectl delete nodepool,ec2nodeclass default
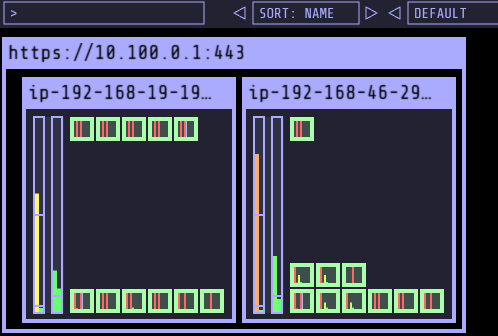
- replicas 5인경우, on-demand 인스턴스 (노드) 추가 확인

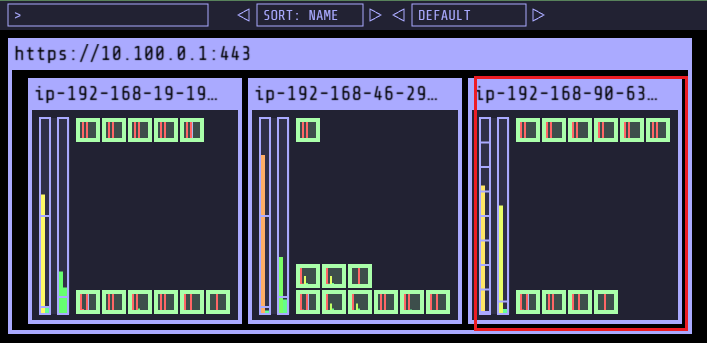
- replicas 12인경우, on-demand 인스턴스 (노드) 추가 확인

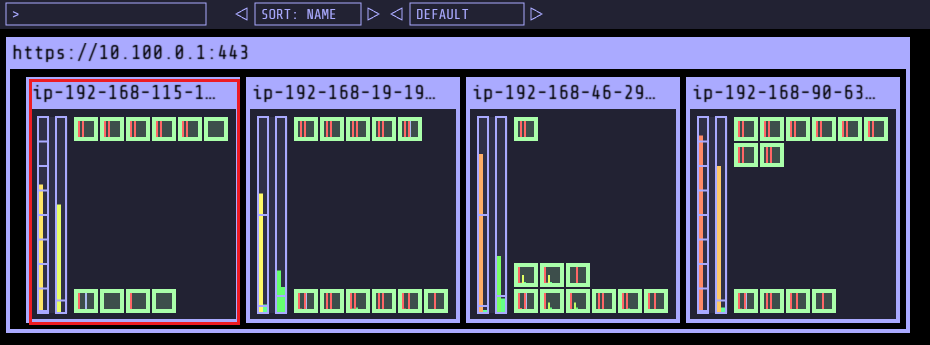
- on-demand 인스턴스 증가 후, replicas 5인경우 Node 삭제 확인

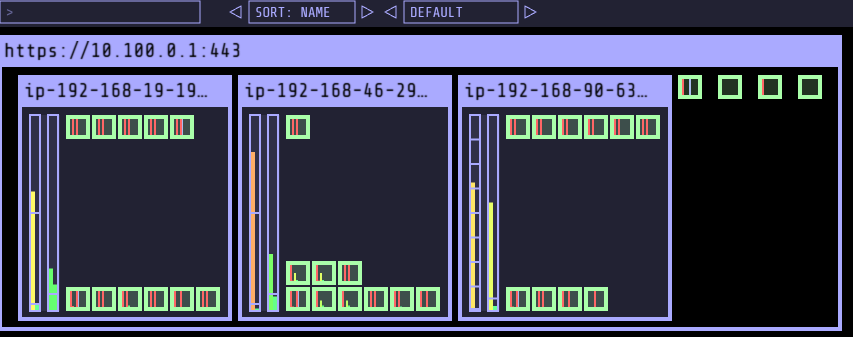
- on-demand 인스턴스 감소 후, replicas 1인경우 Node 삭제 확인
- c6g.2xlarge 인스턴스에서 c6g.large 인스턴스로 스펙 감소 확인


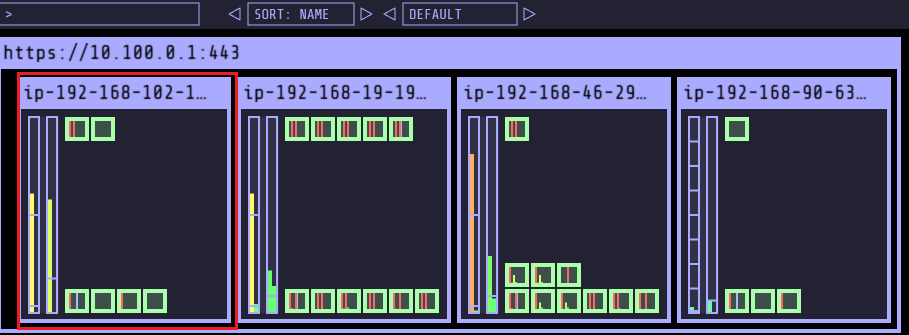
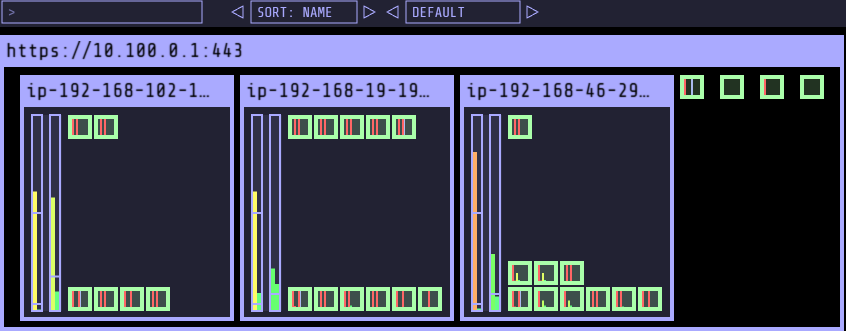
- Spot-to-Spot Consolidation 실습
# 기존 nodepool 삭제
kubectl delete nodepool,ec2nodeclass default
# 모니터링
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
eks-node-viewer --resources cpu,memory --node-selector "karpenter.sh/registered=true"
# Create a Karpenter NodePool and EC2NodeClass
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
requirements:
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: karpenter.k8s.aws/instance-hypervisor
operator: In
values: ["nitro"]
expireAfter: 1h # nodes are terminated automatically after 1 hour
limits:
cpu: "1000"
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized # policy enables Karpenter to replace nodes when they are either empty or underutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- alias: "bottlerocket@latest"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
EOF
# 확인
kubectl get nodepool,ec2nodeclass
# Deploy a sample workload
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 5
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
memory: 1.5Gi
securityContext:
allowPrivilegeEscalation: false
EOF
- 확인 및 replicas 증가/감소
#
kubectl get nodes -L karpenter.sh/nodepool -L node.kubernetes.io/instance-type -L karpenter.sh/capacity-type
kubectl get nodeclaims
kubectl describe nodeclaims
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl logs -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | grep 'launched nodeclaim' | jq '.'
# Scale the inflate workload from 5 to 12 replicas, triggering Karpenter to provision additional capacity
kubectl scale deployment/inflate --replicas 12
# This changes the total memory request for this deployment to around 12Gi,
# which when adjusted to account for the roughly 600Mi reserved for the kubelet on each node means that this will fit on 2 instances of type m5.large:
kubectl get nodeclaims
# Scale down the workload back down to 5 replicas
kubectl scale deployment/inflate --replicas 5
kubectl get nodeclaims
# We can check the Karpenter logs to get an idea of what actions it took in response to our scaling in the deployment. Wait about 5-10 seconds before running the following command:
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
# Karpenter can also further consolidate if a node can be replaced with a cheaper variant in response to workload changes.
# This can be demonstrated by scaling the inflate deployment replicas down to 1, with a total memory request of around 1Gi:
kubectl scale deployment/inflate --replicas 1
kubectl logs -f -n "${KARPENTER_NAMESPACE}" -l app.kubernetes.io/name=karpenter -c controller | jq '.'
kubectl get nodeclaims
# 삭제
kubectl delete deployment inflate
kubectl delete nodepool,ec2nodeclass default
- replicas 5인경우, spot 인스턴스 (노드) 추가 확인

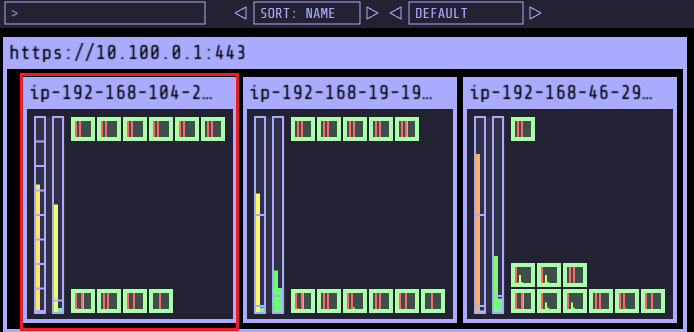
- replicas 12인경우, spot 인스턴스 (노드) 추가 확인

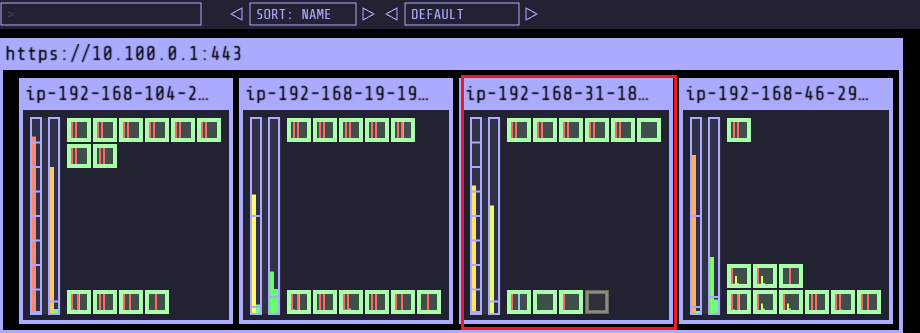

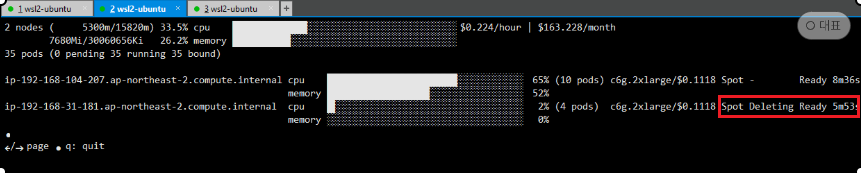
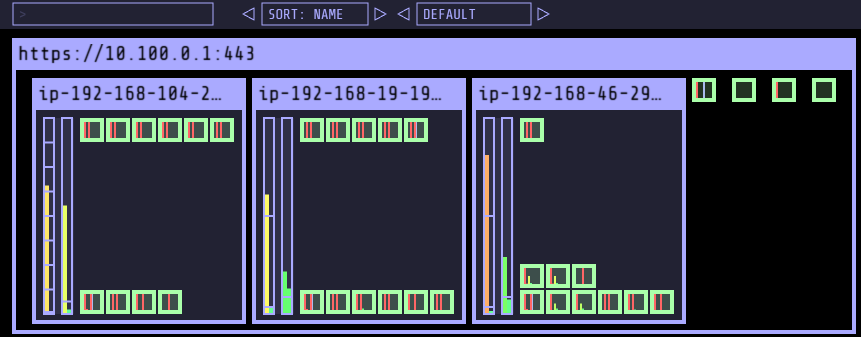
- Spot 인스턴스 증가 후, replicas 5인경우 Node 삭제 확인
728x90
'2025_AEWS Study' 카테고리의 다른 글
| 6주차 - EKS Security - EKS 인증/인가(2) (0) | 2025.03.16 |
|---|---|
| 6주차 - EKS Security - 인증/인가(1) (0) | 2025.03.15 |
| 5주차 - EKS Autoscaling(CAS→Node Autoscaling) (0) | 2025.03.07 |
| 5주차 - EKS Autoscaling(HPA/KEDA/VPA → Pod Autoscaling ) (0) | 2025.03.07 |
| 4주차 - EKS Observability(4) Grafana (0) | 2025.03.02 |